
ChatGPTをはじめとした対話型AIが社会に浸透している今、音声入力にも注目が集まっている。
音声入力はタイピングよりも速くて楽なため、効率化と相性がいい。Claude CodeなどのAIエージェントはエンジニア以外にも認知されつつあるため、それに比例して音声入力の需要も高まるだろうと思っている。
そして、最近は音声認識・テキスト生成(文字起こし)にAI技術を活用した、高精度なツールが数々現れている。これまでは音声入力されたままに出力されていたテキストが、「えーっと、」などの不要な部分の除去や誤変換の修正などを経て、整えられた状態の文章として出力される、といった具合だ。
今回はそんな最近のAI音声入力・文字起こしツール(以下、AI音声入力ツール)から、無料かつ完全なローカル環境でも利用できる「OpenWhispr」を実際に試してみたので、概要や導入手順、使用感などをまとめたい。
最初に書いてしまうと、このOpenWhisprは、
- 外部のクラウドを避けて音声入力・文字起こしを行いたい
- 文字を整えるLLMへのプロンプトを細かく調整したい
- 「Aqua Voice」や「Superwhisper」の費用がネック
- 音声ファイルの文字起こしも行いたい
といった方々は導入を検討する余地があると思う。それでは、内容に入っていこう。
現在の主要なAI音声入力ツール
現在最も注目を集めているAI音声入力ツールは、「Aqua Voice」と「Superwhisper」だと思われる。どちらもほぼリアルタイムで高精度に文字起こしができるツールで、開発者や効率化を目指す経営者などが積極的に導入している印象だ。これらをはじめ、主要なAI音声入力ツールは非常に便利であるものの、
- 費用がかかる
- 外部組織のクラウドを利用する
というものが多い。
費用面では月額制のものが大多数で、ツールを使うには「お金を払い続ける」ということを受け入れる必要がある。
また、音声データや生成されたテキスト情報などは提供会社のクラウドを経由するものが多いので、機密性の高い業務を行う組織などでは導入が難しいかもしれない。
以下に、Aqua Voiceなどの主要なAI音声入力ツールについて、いくつかピックアップしてまとめてみる。
| 主要なツール | 料金 | 運用基盤 |
|---|---|---|
| Aqua Voice | ・無料枠あり(語数制限あり) ・月額8ドル~ | クラウド |
| Superwhisper | ・無料枠あり(小型モデルのみ) ・月額8.49ドル~ ・買い切り249.99ドル | クラウド ※完全ローカル運用可能だが、その場合は文章のLLM処理機能なし |
| Typeless | ・無料枠あり(語数制限あり) ・月額12ドル~(年払いの場合) | クラウド |
| Wispr Flow | 無料枠と試用はあるが、本格利用は有料化しやすい | クラウド |
各種公式サイトはこちら
余談だが、AI音声入力ツールが世の中に広まりつつある背景の一つには、OpenAIが開発したAI音声認識エンジン「whisper」がオープンソースで公開されたことが挙げられる。OpenAIが約68万時間分の音声でトレーニングしたAI音声認識エンジンを、誰でも無料で開発に利用できるようになったのだ。(参考:whisperの公式GitHub)。
また、現在ではソフトだけではなく「AIボイスレコーダー」といったハードとしても、音声入力とAIによる文字起こしは浸透しつつある。

OpenWhisprの概要
OpenWhispr は オープンソースソフトウェアとして開発されたAI 音声入力ツールである。ポイントは以下のとおり。
- OpenAIの「whisper」を利用して開発されている
- 完全なローカル環境でも利用可能
- AIモデルを自由に選べる
- 単語登録などの機能あり
- 誰でも無料でダウンロードして利用できる
- 特定の企業に依存していない
- ソースコードが公開されているので透明性が高い
音声認識にはwhisper系の技術が使われており、純粋なSTT(Speech-to-Text)処理に加えて、LLMによる文章整形も行える。リアルタイム入力だけでなく、mp3などの音声ファイルからの文字起こしにも対応している。
また、上に挙げたポイントの下3点は、オープンソースソフトウェアだからこそのメリットとなる。
入手は公式サイトまたは GitHub から可能となっている(公式サイトはこちら: OpenWhispr)。
クラウド利用で語数の制限なく使いたいのであれば、月額6.67ドル(年払い)からの有料プランに入る必要がある。だが、ローカル環境利用の設定をして、使用するwhisperとLLMのモデルをダウンロードすることで、無料でかつ完全なローカルな環境でも運用することが可能となる。
導入方法
私の導入環境
今回は、ノートPCとデスクトップPCの2つの環境で導入してみた。
なお、完全なローカル環境で使用したい場合、
- アプリ本体(約720MB)
- 音声認識エンジンのモデル(70MB~2GBほど)
- LLMのモデル(1GB~20GB)
の3つが入るようなストレージの空き容量が必要になる。
音声認識エンジンとLLMのモデルは、容量の大きさが異なる複数のモデルから自由に選ぶことができる。
ノートPC
モデル…マウスコンピューター X4-i7
- OS… Windows11 home
- CPU… Intel Core i7-10510U
- GPU…なし(CPU内蔵)
- メモリ…16GB(DDR4)
- ストレージ…SSD 256GB
デスクトップPC
モデル…自作PC
- OS… Windows11 home
- CPU… AMD Ryzen 5 8400F
- GPU… AMD Radeon RX7600(8GB)
- メモリ…32GB(DDR5)
- ストレージ…SSD 256GB、HDD 1TB
ダウンロードとインストール
まずはOpenWhisprの公式サイトからアプリをダウンロードし、PCにインストールする。
私がダウンロードしたのはWindows(Installer)である。
インストール画面では、案内に従ってインストール先のフォルダを選択し、インストールを開始する。
セットアップ
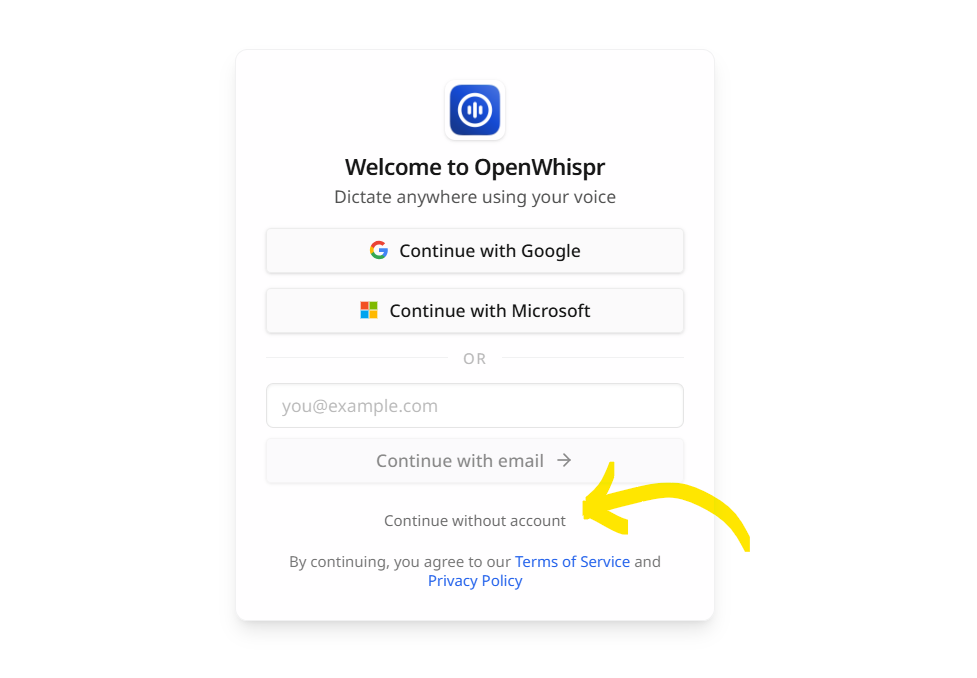
最初にアプリを使用する際に、セットアップが必要になる。
はじめに、アカウントを作成するか確認される。ここでは「Continue without account」を選択することで、アカウントを作成せずに利用することができる。
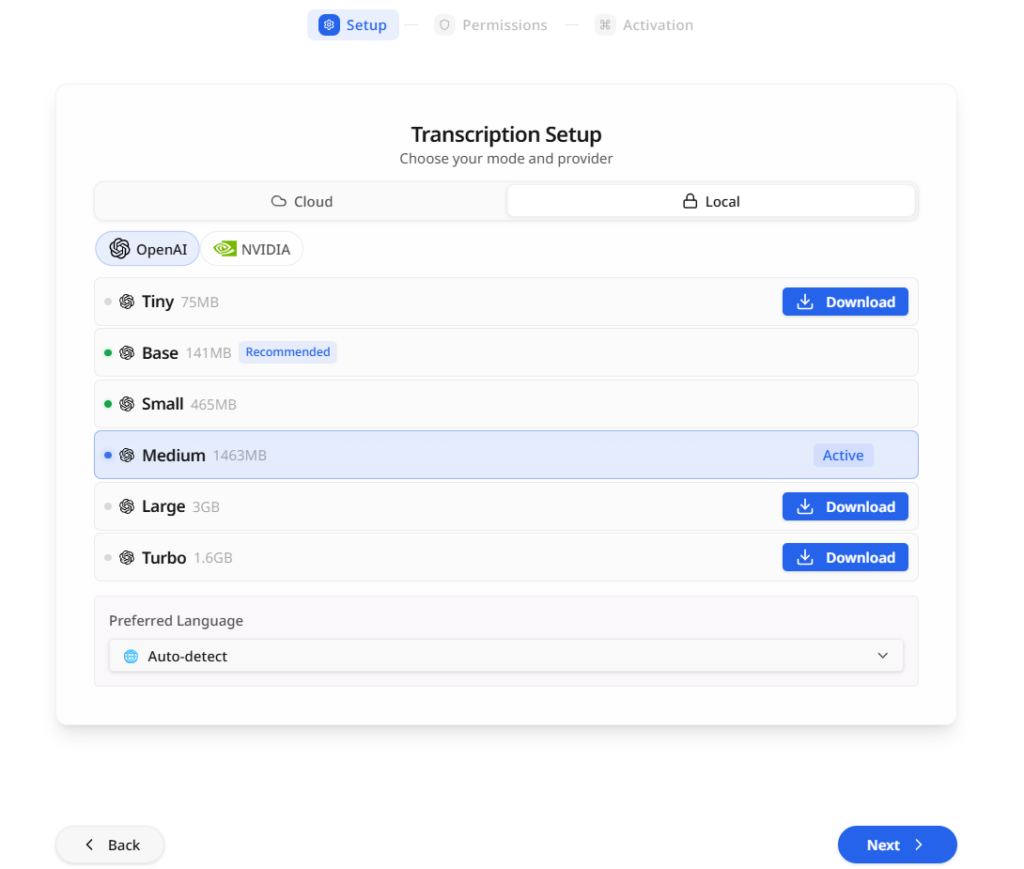
そして、次に使用する音声認識エンジンのモデルを選択する。無料アカウントを作成している場合は制限付きのCloudが利用できるが、アカウントを作成していない場合やローカル環境で運用したい場合は、Localから選択することとなる。LocalにはOpenAI系とNVIDIA系があり、OpenAI系ではTinyからTurboまで複数モデルを選択できる。モデルサイズが大きいほど高精度だが、その分容量が大きく、処理も重くなる。
私は最初、OpenAIの中からおすすめとされているBaseを選んで使用してみたが、その後Mediumのモデルを適用させた。速度よりも精度を優先したかったためだ。
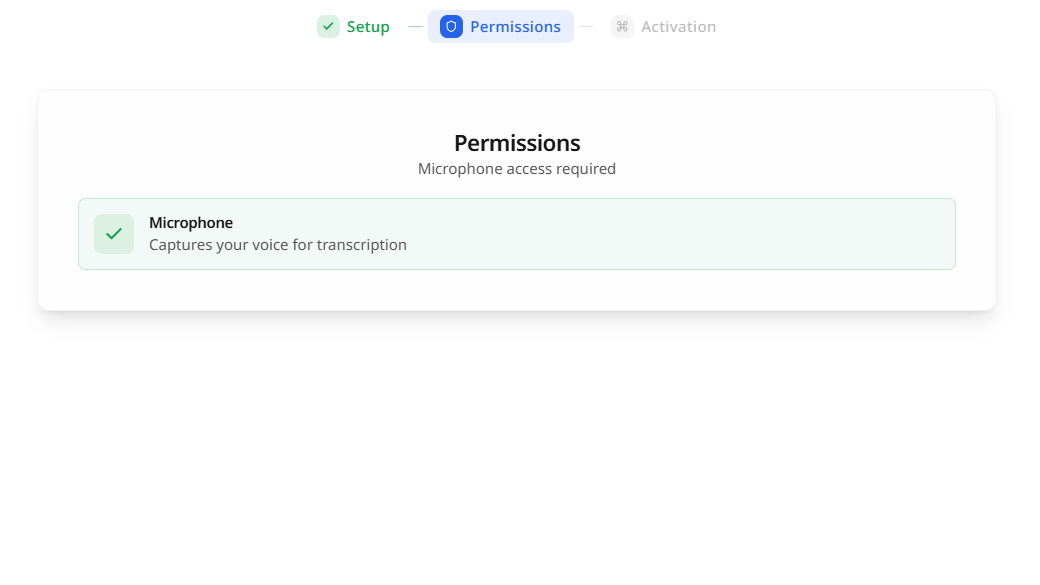
その後、マイク使用の権限について設定する。マイクが使用できるようになるとチェックマークがつく。
最後に、音声入力を呼び出すホットキー(ショートカットキー)を設定する。
私は Ctrl + Space に設定した。
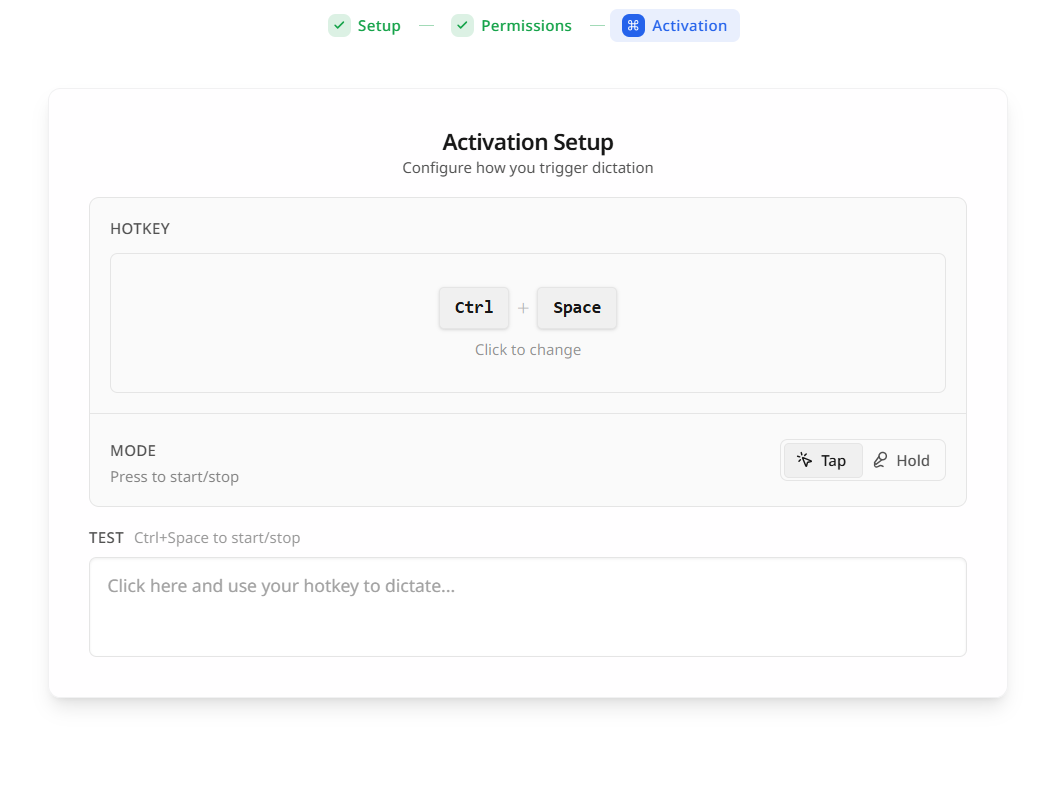
これで、基本のセットアップは完了となり、アプリを使用することができるようになる。
LLMモデルの設定
OpenWhisprのセットアップ画面ではLLMモデルの設定がなかったが、音声認識エンジンと同様に、アカウントを作成していない場合やローカル環境で運用したい場合は、LLMモデルを選択してダウンロードする必要がある。
LLMモデルの選択とダウンロードは、アプリの設定画面内にある「Language-Models」から行うことができる。
モデルは、中国のアリババグループが開発した「Qwen」やMeta社の開発した「Llama」、Google社の「Gemma」など、様々な企業のモデルから選ぶことができる。
なお、これらはオープンソース化されているモデルであるため、透明性も高いと言える。
私はQwen3.5の9Bのモデル(約5.5GB)を選択し、ダウンロードした。
また、この設定画面の下段では、LLMに指示する内容(プロンプト)を編集することもできる。そのため、例えば「要点を箇条書きを使って簡潔にまとめて」といった指示を追加するなどして、出力をカスタマイズすることが可能となっている。
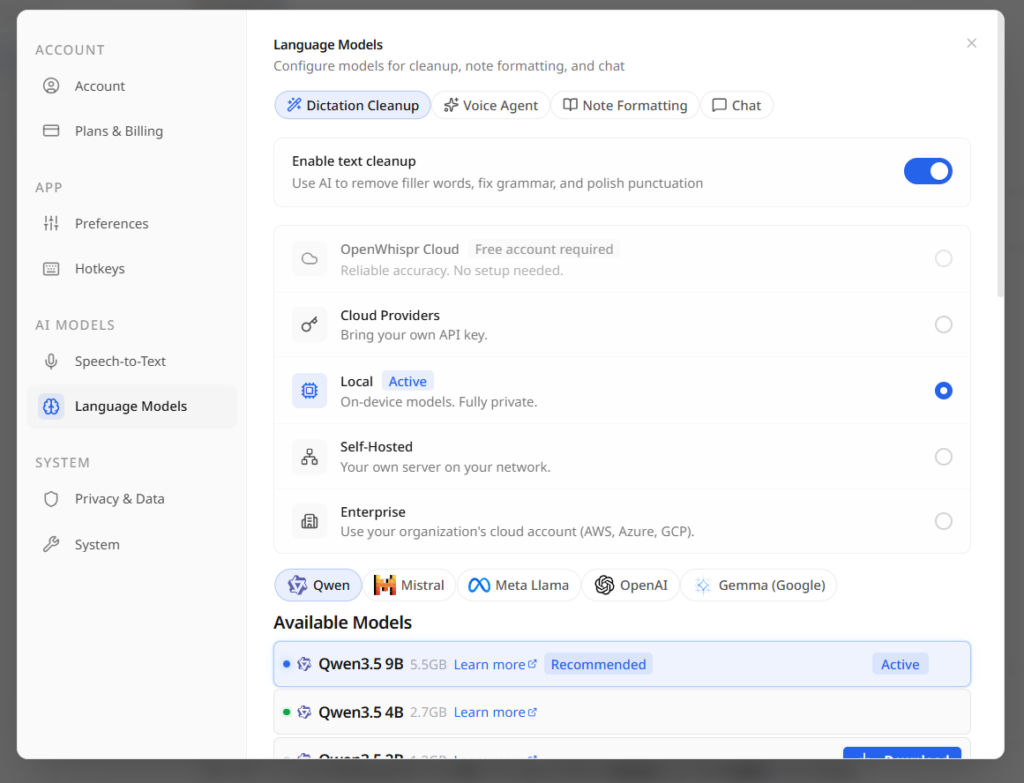
設定画面(LLMモデル)その他、アプリの画面では以下の機能の設定があるため、利用するとさらに利便性が増すはずだ。
- Dictionary
単語登録機能。地名や人名などの固有名詞を登録しておくと、認識精度を上げやすい。 - Integrations
APIやMCPサーバーなどの外部連携設定を行うことができる。
実際に使ってみた感想
操作感
アプリの操作感としては、次のとおりである。
- ホットキーですぐに入力を開始できるのが嬉しい。
- アプリを起動するとPC画面右下にOpenWhisprのアイコンが常駐してくれるので、いつでも文字起こしができる状態なのだと分かるのがいい。
- 基本操作は「開始キーを押す → 話す → 再度キーを押して終了 → 文字起こし完了を待つ」という流れ。
- 出力結果はカーソル位置に挿入されるだけでなく、ホーム画面にも履歴として残るため、過去に文字起こしした内容も再利用しやすい。
- 音声入力して文字起こしする以外にも、音声データを取り込んで文字起こしさせることもできる。
精度
文字起こしの精度は、利用するモデルと音声入力の質によるようだ。最初はPC本体のマイクを利用していたが、外付けマイク(ダイナミックマイク)を利用して音声入力した方が精度の良い文章が生成された。
以下は、アーネスト・ヘミングウェイの小説『老人と海』の冒頭の音読をOpenWhisprで文字起こししてみた結果である。音声入力にはダイナミックマイクを使用、音声認識エンジンはmedium、LLMモデルはQwen3.5 9Bといった設定だ。

次に、比較用としてWindows標準の音声入力機能と、Googleドキュメントの音声入力機能を試してみた。

私の発音の善し悪しはさておき、内容を比較してみると、OpenWhisprもまずまずの精度で出力できている。WindowsやGoogleの音声入力機能では句読点などが入らないが、OpenWhisprではLLMによる文章調整が行われるためか、句読点などがおおむね正しく入れ込まれていた。
処理速度
処理速度の体感としては、「話した時間の約2倍ほど待つ」といった具合だった。
これは音声認識エンジンやLLMのモデルにもよる。だが、比較的軽い音声認識エンジンモデルであるbaseやtinyでは、処理が速いものの精度が悪く、実用は少し厳しいと感じた。
GPUを積んでいるデスクトップPCでも試してみたが、速度はノートPCの場合とあまり変わらなかったように感じた。調べたところでは、WhisperはNVIDIA製GPUで速度を上げられるという話もあった。筆者環境ではGPU加速が効かず、CPU処理になったと思われる。
WindowsやGoogleの音声入力機能はほぼリアルタイムで処理してくれるため、速度面ではこれらの方が優れている。
まとめ
今回はオープンソースソフトウェアのAI音声入力ツールである「OpenWhispr」を実際に使用してみた。
リアルタイムに文字を生成するといったことは苦手なものの、音声情報からある程度のクオリティで文字起こしができるのは悪くないと感じた。設定や実行環境によっては、もっと快適に使うことができるかもしれない。
何といっても、こういった機能を無料かつ完全にローカルな環境で利用できるのはOpenWhisprのメリットだろう。
音声入力ツールへの課金を考え直したい人や、外部クラウドを経由させることに躊躇している人は、一度ダウンロードして試してみるとよいと思う。


コメント